
Điều đó thực sự có nghĩa gì khi nói rằng một agent “hiểu” công ty?
Không phải là khả năng tìm kiếm trong các công cụ. Không phải là đọc được tài liệu. Mà là khả năng nắm bắt cách công ty vận hành trong thực tế — giống như cách một chief of staff giỏi làm được sau vài tháng.
Họ không chỉ nhìn vào sơ đồ tổ chức để biết ai ra quyết định, mà biết ai thực sự có quyền lực. Họ không chỉ đọc Slack, mà biết kênh nào có thông tin thật và kênh nào chỉ mang tính hình thức. Họ hiểu một deal “đóng” trong CRM tháng 3, nhưng thực ra đã được chốt từ tháng 1 qua một cuộc gặp không ai ghi lại. Và quan trọng nhất, họ biết điều gì vừa thay đổi và vì sao nó quan trọng ngay lúc này.
Sự hiểu đó không đến từ một nguồn dữ liệu duy nhất, mà từ việc tổng hợp hàng trăm tín hiệu rời rạc thành một bức tranh thống nhất. Và hiện tại, không có agent nào làm được điều này.
Có quyền truy cập không đồng nghĩa với hiểu
Hầu hết các công ty đã đi khá xa ở bước “access”. Agent được kết nối với Slack, Google Drive, CRM thông qua API, MCP server hoặc các lớp integration khác. Về mặt lý thuyết, chúng có thể chạm tới toàn bộ dữ liệu của tổ chức.
Nhưng khi bạn bắt đầu hỏi những câu hỏi đơn giản, mọi thứ nhanh chóng lộ ra vấn đề.
Hỏi ai đang phụ trách khách hàng lớn nhất, agent sẽ tìm trong Gmail và đưa ra một cái tên. Hỏi lại qua một công cụ khác, bạn có thể nhận một cái tên hoàn toàn khác. Hỏi về ưu tiên quý này, nó sẽ trích từ một tài liệu chiến lược — kể cả khi tài liệu đó đã lỗi thời nhiều tháng.
Vấn đề không nằm ở việc không tìm được dữ liệu. Vấn đề là agent tìm quá nhiều, không phân biệt được cái nào còn актуальный, không giải quyết được mâu thuẫn giữa các nguồn, nhưng vẫn trình bày một mảnh thông tin như thể đó là toàn bộ sự thật.
Access chỉ có nghĩa là chạm được dữ liệu. Understanding là biết dữ liệu đó có ý nghĩa gì trong toàn bộ bối cảnh.
Một nhân viên mới có thể có full access ngay ngày đầu tiên. Nhưng phải mất hàng tháng để họ hiểu công ty. Chính khoảng cách đó là thứ mà các hệ thống hiện tại chưa chạm tới.
Ngành đang giải sai bài toán
Phần lớn hạ tầng AI hiện nay xoay quanh một câu hỏi: làm sao đưa đúng thông tin đến agent vào đúng thời điểm. Từ RAG, vector database, semantic search đến MCP server — tất cả đều là các biến thể của cùng một ý tưởng: khi cần thì đi tìm.
Nhưng cách tiếp cận này có một vấn đề cốt lõi. Mỗi lần agent cần context, nó bắt đầu lại từ con số 0. Không có trí nhớ tích lũy, không có hiểu biết lâu dài, không có cảm nhận về việc điều gì đã thay đổi kể từ lần trước.
Nó giống như việc mỗi sáng bạn tuyển một nhân viên mới, cấp toàn quyền truy cập, và yêu cầu họ ra quyết định trước buổi trưa. Họ sẽ tìm được thông tin, nhưng sẽ sai rất nhiều — và bạn sẽ phải dành thời gian sửa lại.
“Bộ não công ty”: từ retrieval sang synthesis
Cách tiếp cận thay thế là xây dựng một lớp hiểu biết liên tục — một “bộ não” của công ty.
Thay vì tìm kiếm mỗi khi có câu hỏi, hệ thống duy trì một mô hình luôn được cập nhật về thực tế của tổ chức. Agent không cần đi tìm nữa, mà chỉ cần đọc từ mô hình đó — nơi câu trả lời đã tồn tại sẵn.
Sự khác biệt này tưởng nhỏ nhưng mang tính bản chất. Retrieval chỉ trả về những mảnh rời rạc, còn synthesis tạo ra một worldview nhất quán.
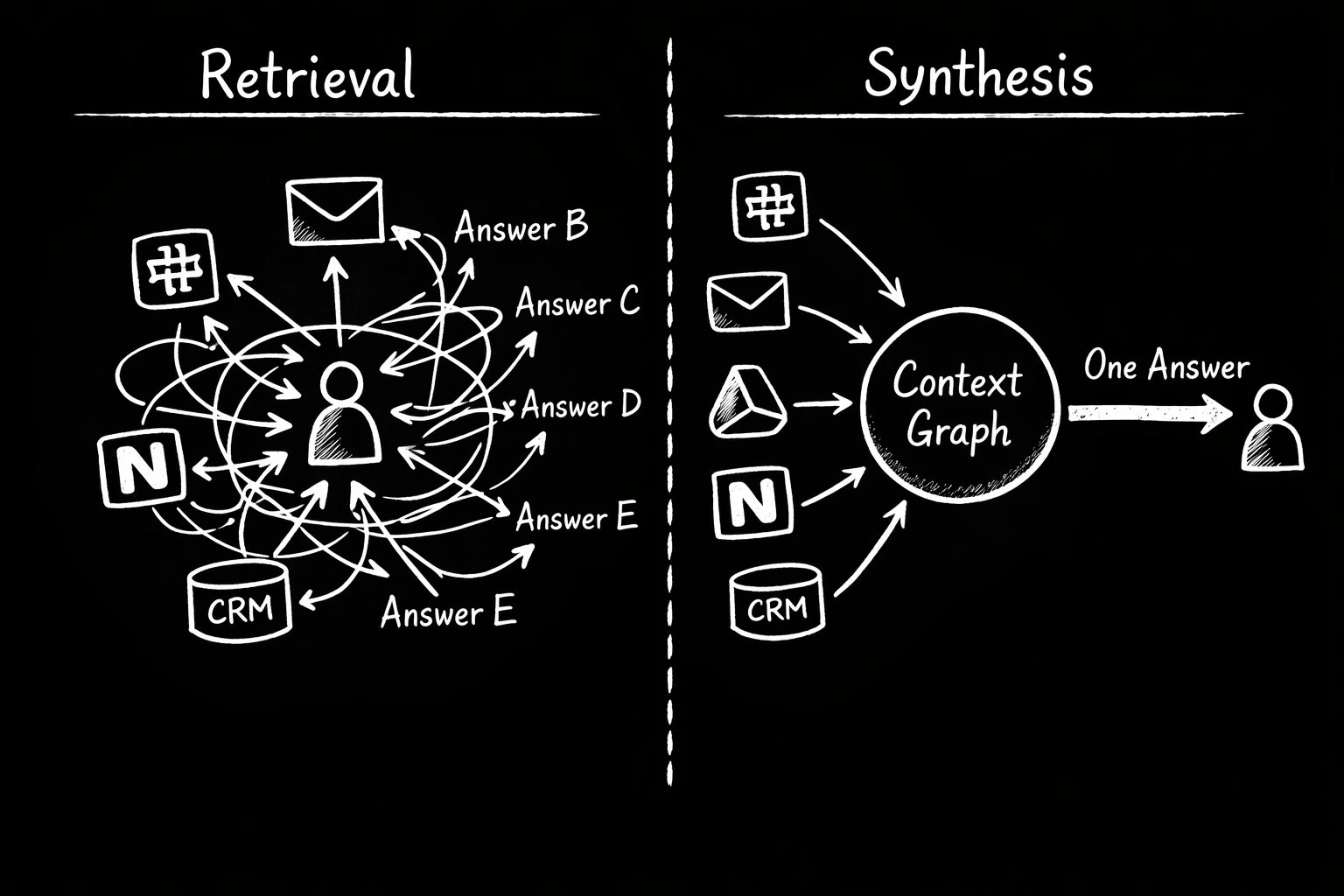
Để làm được điều đó, hệ thống phải giải quyết những vấn đề mà hiện tại hầu như bị bỏ qua.
Dữ liệu trong công ty luôn mâu thuẫn. Một deadline có thể xuất hiện khác nhau trên Slack, công cụ quản lý dự án và trong cuộc họp gần nhất. Một hệ thống chỉ tìm kiếm sẽ trả về cái đầu tiên nó thấy. Một hệ thống hiểu phải biết đánh giá nguồn nào đáng tin hơn và đưa ra câu trả lời duy nhất.
Danh tính cũng bị phân mảnh. Cùng một người có thể xuất hiện dưới nhiều dạng khác nhau trên email, Slack, CRM và lịch họp. Nếu không hợp nhất được những biểu diễn này, hệ thống không bao giờ có được cái nhìn đúng.
Thông tin thì liên tục lỗi thời. Một tài liệu cách đây sáu tháng không thể có cùng trọng số với một tin nhắn vừa gửi mười phút trước, nhưng hệ thống retrieval lại đối xử chúng ngang nhau.
Và quan trọng hơn, nhiều insight không tồn tại rõ ràng trong bất kỳ tài liệu nào. Chúng chỉ xuất hiện khi bạn kết hợp nhiều nguồn lại với nhau — điều mà con người làm rất tốt, nhưng máy móc thì chưa.
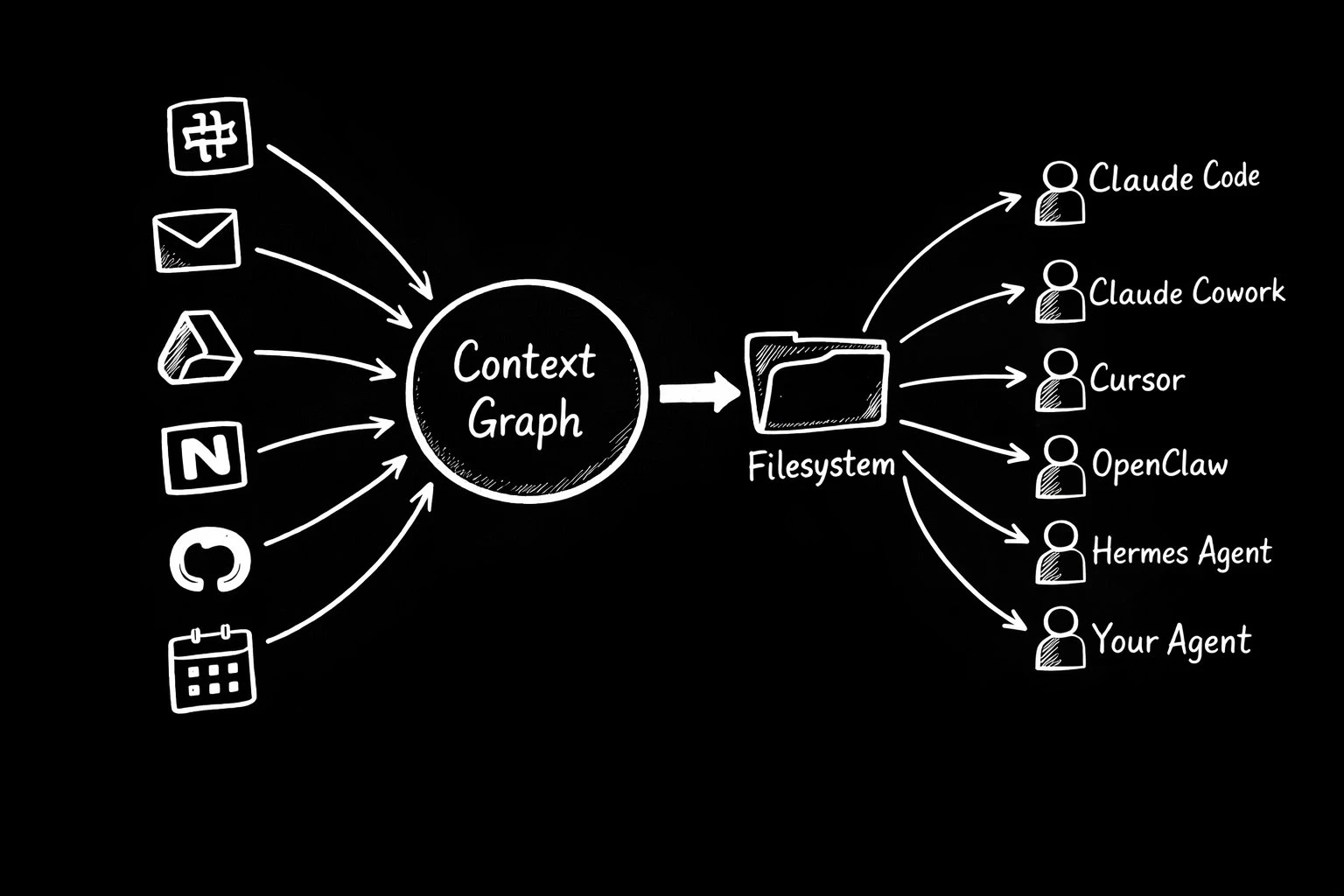
Filesystem chỉ là giao diện, không phải giải pháp
Một điểm thú vị là cách “phân phối” hiểu biết này không cần phức tạp. File system — thứ mọi agent đều đã hỗ trợ — có thể trở thành giao diện chung. Context của công ty được materialize thành các file có cấu trúc, luôn được cập nhật, và agent chỉ việc đọc.
Nhưng bản thân file không phải là “bộ não”. Chúng chỉ là output. Giá trị thực nằm ở lớp synthesis phía trước — nơi dữ liệu thô được diễn giải, hợp nhất và biến thành hiểu biết.
Lợi thế cạnh tranh thật sự nằm ở thời gian
Hiểu biết về một công ty không thể được “mua ngay”. Nó phải tích lũy.
Ngày đầu tiên, hệ thống biết rất ít. Sau vài tuần, nó bắt đầu nhận ra pattern. Sau vài tháng, nó có một mô hình đủ sâu để đưa ra những câu trả lời đáng tin cậy. Mỗi dữ liệu mới không chỉ thêm thông tin mà còn làm giàu toàn bộ bức tranh.
Vì vậy, lợi thế không nằm ở công nghệ — thứ có thể bị sao chép — mà nằm ở lượng hiểu biết đã tích lũy theo thời gian. Công ty nào bắt đầu sớm sẽ có một khoảng cách mà tiền không thể bù đắp.
Kết luận
Năm 2025, ngành tập trung vào việc mở quyền truy cập: connector, integration, MCP. Đó là bước cần thiết, nhưng hóa ra lại là phần dễ.
Năm 2026 sẽ là cuộc chơi của understanding. Không phải là có bao nhiêu dữ liệu, mà là hiểu dữ liệu đó đến đâu. Không phải là truy xuất nhanh hơn, mà là xây dựng một mô hình thực tế chính xác hơn.
Công ty của bạn không cần thêm công cụ để kết nối.
Công ty của bạn cần một hệ thống thực sự hiểu nó.